
Robts.txt چیست و چه کاربردی دارد؟

آیا میدانید Robots.txt چیست و چه کاربردی دارد؟ مکانیسم کارکرد آن به چه صورت است؟ چگونه Robots.txt را بسازید یا بهینه کنیم؟ با آیتی هما همراه باشید تا در مورد این مقوله مهم در سئو بیشتر بدانید و با چگونگی عملکرد و همچنین کاربرد Robots.txt آشنا شوید.
همانطور که میدانید پررنگترین نقش در امتیازدهی به میلیونها صفحات وب توسط رباتهای گوگل انجام میگیرد.گوگل بهعنوان بزرگترین موتور جستجوی جهان با تسلط بالای خود در سهم جستجوی کاربران در اینترنت؛ رباتهای زیادی را بهمنظور رنکینگ و امتیازدهی وبسایتها تولید و گسترش داده است. این رباتها مطابق الگوریتمهای تعیینشده توسط گوگل به جمعآوری اطلاعات از سایتها میپردازند. متخصصان سئو بهطور روزانه چگونگی عملکرد و تغییرات این ربات را رصد و تحلیل میکنند و طبق رویکرد رباتها عملیات سئوی خود را بهبود میدهند. اینجا سؤالاتی در ذهن شکل میگیرد؛ این رباتها به چه صورت به سایتها دسترسی پیدا میکنند؟ به چه روشی میتوان دسترسی این باتها به سایتمان را محدود کرد و یا دسترسی کامل به آنها داد؟
برای پاسخ به این سؤالات باید اطلاعاتی جامع در مورد Robots.txt و چگونگی عملکرد و کاربرد آن کسب کنید.
این تکنیک یکی از مهمترین و حیاتیترین تکنیکها در سئوی تکنیکال است. در این تکنیک با درج دستوراتی در فایلی متنی به نام Robots.txt میتوانید میزان دسترسی رباتهای گوگل به سایتتان را تعریف کنید.
Robots.txt یک شمشیر دو لبه است! درواقع استفاده صحیح و اصولی از آن میتواند بهشدت روی ارتقا رتبهی شما در گوگل تأثیر بگذارد و در نقطه مقابل چشمپوشی و بیدقتی در این تکنیک میتواند باعث بروز خسارت جدی به سئوی وبسایت شما شود. در ادامه مقاله شمارا با Robots.txt بیشتر آشنا خواهیم کرد و اهمیت آن برای موفقیت در سئوی سایت را موردبررسی قرار خواهیم داد. با ما همراه باشید.
فایل Robots.txt چیست؟
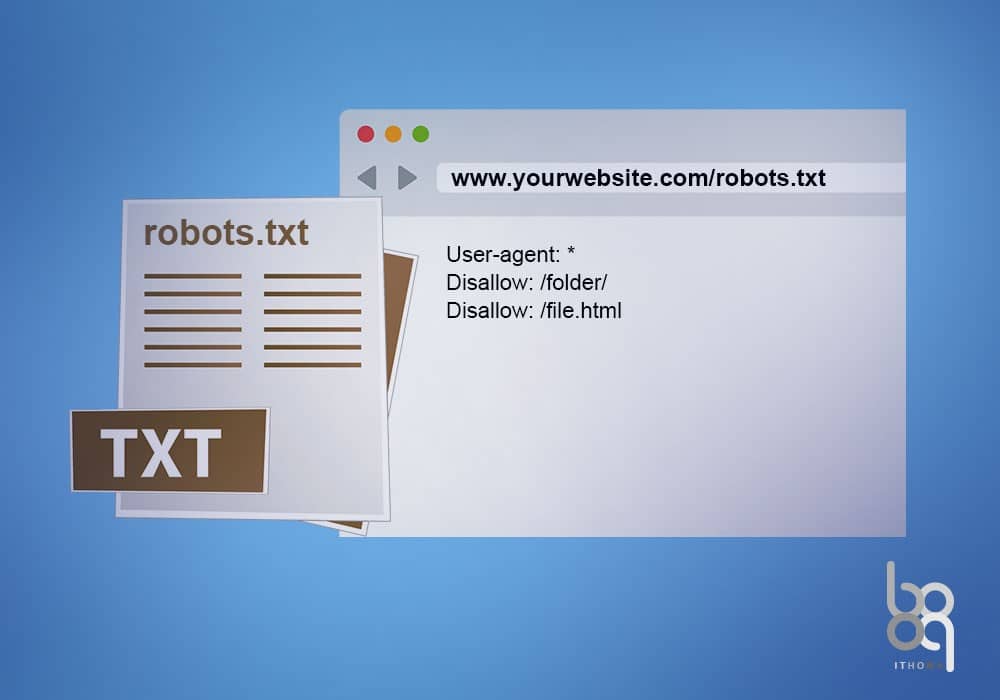
فایل Robots.txt یک فایل متنی است که در روت دایرکتوری (Root Directory) یا همان مسیر اصلی سایت قرار دارد.درواقع وظیفهی اصلی این فایل اعلام و تعیین مجوز قسمتهای قابلدسترسی و قسمتهای غیرقابلدسترسی به خزندگان (Crawlers) گوگل است. همانطور که گفتیم وظیفهی این خزندگان بررسی و جمعآوری اطلاعات از سایت شما برای موتور جستجوی گوگل است.با درج دستورات در فایل Robots.txt به رباتها یا خزندگان گوگل میتوانید بگویید کدام صفحات را بررسی و ایندکس کنند و از کدام صفحات یا بخشهای سایت را نادیده بگیرند.
ربات و خزندگان وقتی بهمنظور بررسی وارد سایتی میشوند با اولین چیزی که روبرو میشوند همین فایل Robots.txt است و بهمحض رسیدن به این فایل محتوای فایل را بررسی کرده و طبق دستورات شروع به کاوش در صفحات سایت شما میکنند. همانطور که گفتیم فایل Robots.txt باید در روت اصلی سایت شما برهاست قرار بگیرد و آدرس دسترسی به آن بهصورت url زیر خواهد بود.
اگر سایتی فاقد فایل robots.txt باشد چه اتفاقی میافتد؟

اگر فایل Robots.txt در روت اصلی سایت آپلود نشده باشد و یا در مسیر دیگری قرار داشته باشد، خزندگان گوگل بهتمامی محتوای سایت دسترسی خواهند داشت و تمامی صفحات سایت ایندکس میشود، این باعث خواهد شد که صفحات بیارزش شما نیز ایندکس شوند و معدل کارنامهی رتبه شما در گوگل پایین دچار کاهش و افت شود. از طرفی عدم استفاده از این فایل میتواند باعث اشغال منابع هاست یا سرور شما شود چون هزاران ربات در طول روز به سایت شما سر میزنند و با بررسی دوبارهی تمام صفحات موجب ترافیک سنگینی روی سایت شما میشوند.
چگونگی عملکرد فایل robots.txt

همانطور که پیشتر گفته شد؛ فایل Robots.txt ساختاری ساده دارد و درج دستورات در آن به خزندگان و رباتهای گوگل کمک میکند تا دقیقاً بدانند کدام صفحات را بررسی و کدام صفحات را بررسی نکنند.
از مهمترین و متداولترین دستورات robots.txt دستوراتی مانند User-agent، Disallow، Allow و Sitemap میباشد. در ادامه بهصورت تفکیکشده به شرح این دستورات میپردازیم:
User-agent:
این دستور به رباتها و خزندگان موتورهای جستجو (نه فقط موتور جستجوی گوگل) اجازه دسترسی بهتمامی بخشهای وبسایت را میدهد. اگر تصمیم دارید که اطلاعات سایت فقط توسط رباتهای گوگل بررسی و ایندکس شود باید نام ربات گوگل را بهصورت دقیق بهجای علامت * درج کنید. بهعنوانمثال کد زیر مجوز دسترسی فقط به رباتهای گوگل را صادر کرده است.
User-agent: Googlebot

و یا کد زیر مجوز دسترسی به صفحات را فقط به رباتهای موتور جستجوی بینگ داده است.
User-agent: Bingbot
دستور Disallow و Allow:
و یا کد زیر مجوز دسترسی به صفحات را فقط به رباتهای موتور جستجوی بینگ داده است.
User-agent: Bingbotبا استفاده از دستورات Disallow و Allow میتوان به رباتهای موتورهای جستجوی دستور داد که چه صفحاتی را بررسی کنند و یا چه صفحاتی را نادیده بگیرند. کد Allow برای ایجاد دسترسی به رباتها و کد Disallow برای ایجاد محدودیت برای رباتها کاربرد دارد.بهعنوانمثال اگر شما در فایل Robots.txt دستور “Disallow: /” را درج کرده باشید با این دستور به رباتها و خزندگان موتورهای جستجو میفهمانید که هیچکدام از صفحات سایت را بررسی و ایندکس نکنند؛ همچنین اگر بهجای این دستور از کد”Allow: /” استفاده کنید به معنای دادن مجوز کامل به رباتها بررسی و ایندکس صفحات سایت خواهد بود. شما میتوانید با درج آدرس صفحات جلوی این دستورات بهصورت سفارشی تعیین کنید که چه صفحاتی توسط رباتهای موتورهای جستجو بررسی و چه صفحاتی بررسی نشوند. به دستورات زیر بهعنوانمثال توجه کنید:
Disallow: /wp-admin/
Allow: /about/
همانطور که در این مثال ملاحظه میکنید ما به رباتها و خزندگان اعلام کردهایم که پنل مدیریتی سایت ما را بررسی و ایندکس نکنند اما صفحهی درباره ما سایت را بررسی و ایندکس کنند. به همین سادگی میتوان دسترسیها را برای رباتها مدیریت کرد.
Sitemap:
با درج دستور Sitemap: در فایل robots.txt میتوانید آدرس دقیق فایل سایت مچ (برای اطلاعات بیشتر لطفاً مقالهی سایت مچ چیست را مطالعه کنید) را به رباتهای گوگل بدهید تا با پیدا کردن آن به ساختار و صفحات سایت شما بهراحتی و سهولت دسترسی پیدا کنند و شروع به بررسی و ایندکس آن صفحات کنند. البته روش دیگر ثبت سایت مچ از طریق پنل سرچ کنسول گوگل است اما این روش این روش سادهتر است و اگر این روش را هم انجام دهید میتوانید نسبت به دیده شدن صفحات و ایندکس آن اطمینان بیشتری حاصل کنید.
مثالی از کد دستوری معرفی سایت مچ در فایل Robots.txt:
Sitemap: https://yoursite/sitemap.xml
نتیجهگیری
robots.txt مبحثی نیست که قصد داشته باشید برای آموزش آنوقت زیادی بگذارید، با گذر زمان و آزمون خطاها به علم و تجربه این مبحث خواهید رسید. در این مقاله به بررسی Robots.txt پرداختیم و با عملکرد، ساختار و کاربرد آن و همچنین دستورات متداول آن آشنا شدیم. امیدواریم این مقاله از آیتی هما توانسته باشد راهنمای خوبی برای شما باشد، لطفاً اگر تجربه یا نظری در مورد Robots.txt دارید در بخش نظرها ثبت کنید.
